M言語実践
※使用データは「疑似個人情報生成」様で生成したダミーです
関数の仕様を確認する方法
「#shared」と打ち込むと関数一覧が表示される
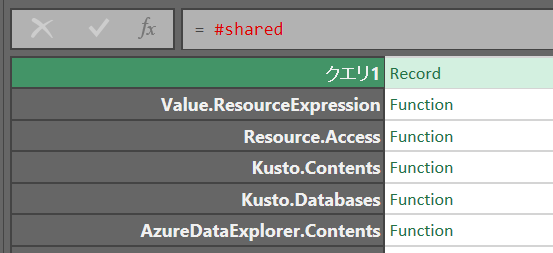
テーブルに変換:= Record.ToTable(#shared)
これでフィルターが使えるようになる
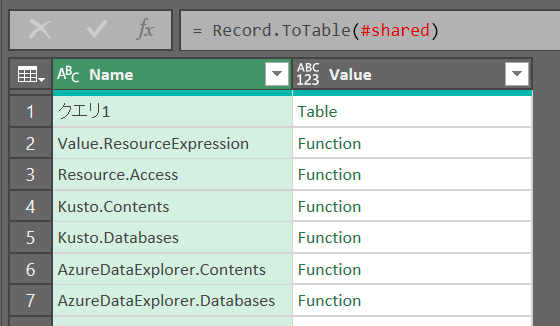
最初から部分一致検索するコード
= Table.SelectRows(Record.ToTable(#shared), each Text.Contains([Name], "Excel"))
// "Excel"を探したいキーワードに置き換える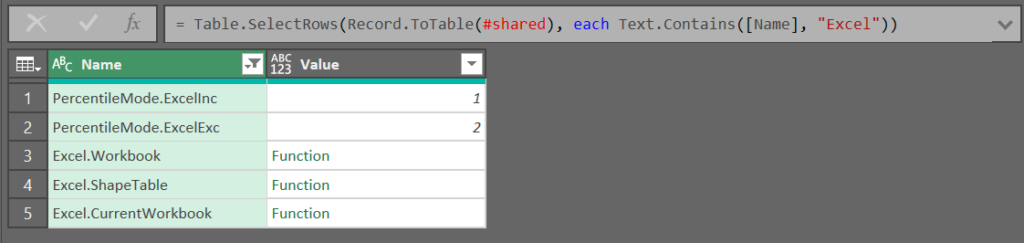
数式バーに関数名をコピペすると仕様が表示される
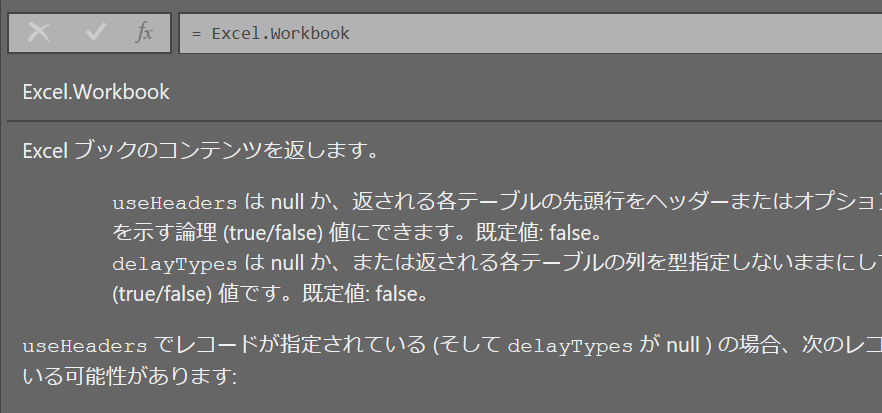
データの取得
ブック内のテーブルを取得する
= Excel.CurrentWorkbook(){[Name="テーブル1"]}[Content]他のブックから取得する
FILE_PATH = "D:\いろいろまとめ\2023年8月\M言語練習.xlsx",
ソース = Table.PromoteHeaders(Excel.Workbook(File.Contents(FILE_PATH), null, true)
{[Item="Sheet1",Kind="Sheet"]}[Data], [PromoteAllScalars=true])Table.PromoteHeaders:1行目をヘッダーにする関数
Excel.Workbook:Excelブックに接続する関数。後の行指定{}内で取得したいデータを設定する。
最初にFILE_PATHを分離しておくことで、ソース元を確認しやすくする
LOOKUPテーブルの作成
絶対にバッファしておくこと
バッファとはよく使う情報を使い回せるように記憶しておくこと(キャッシュと同じ
これやらないと処理速度が非常に遅くなる
処理中に画面右下に数十MBダウンロード中…みたいな表示が出てたら何かがバッファできてない
「バッファすると逆に遅くなる」説はデータベースと接続してSQLを使ってる場合の話であり、CSVやExcelからデータを取得してる場合は気にする必要なし
= Table.Buffer(テーブル名)主キーの設定
検証してないけどこれも処理が早くなるらしい
主キーは重複がないことが必須条件

= Table.AddKey(テーブル名, {"主キー列の名前"}, true)フィルター:Table.SelectRows

条件がテーブル内にある場合(簡単)
each のあとに条件文を書く ()で囲まなくても問題なく動く
= Table.SelectRows(ソース, each ([血液型] = "O"))リストでフィルター:List.Contains
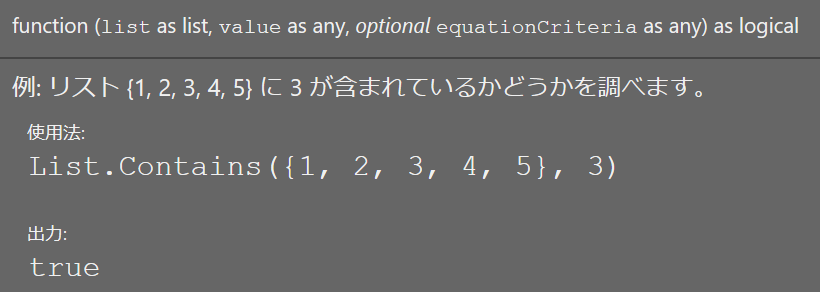
フィルターで使う場合のテンプレ
= Table.SelectRows(テーブル名, each List.Contains(リスト, [列名]))・第1引数(「リスト」の部分)は他テーブルのキー列を指定
・第2引数([列名]の部分)はメインテーブルのキー列を指定
List.Containsの使用例
状況
・都道府県別の天気予報テーブルがある(LOOKUPテーブル)
・メインテーブルには都道府県名だけある
・天気予報が「雨」の都道府県だけを抽出したい
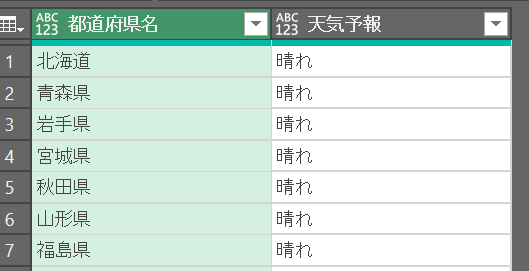
手順1:LOOKUPテーブルを「雨」でフィルター
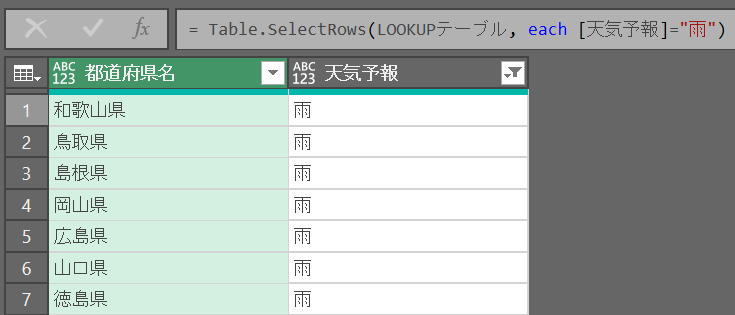
手順2:キーとなる列名を指定して「キーのリスト」を取得
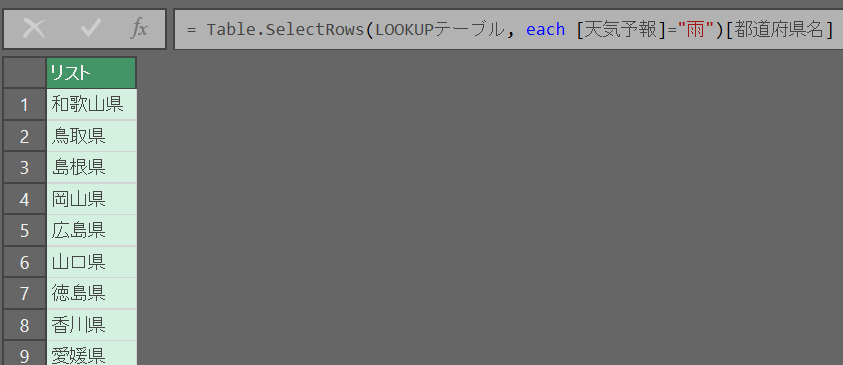
手順3:「キーのリスト」を使ってフィルターする
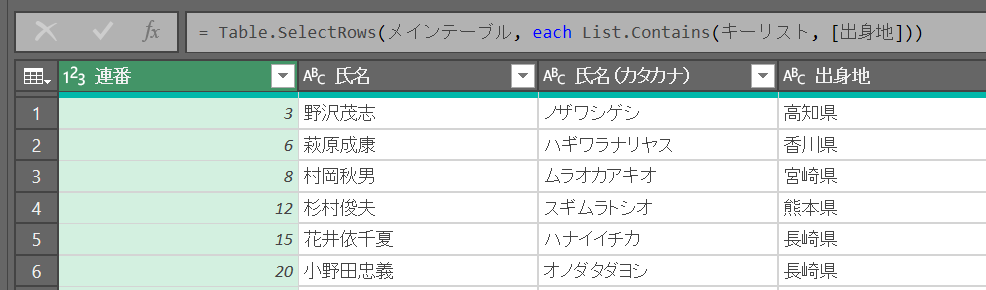
これをM言語でまとめて書くと3ステップに圧縮できる
let
FILE_PATH = "D:\いろいろまとめ\2023年8月\M言語練習.xlsx",
ソース = Table.PromoteHeaders(Excel.Workbook(File.Contents(FILE_PATH), null, true)
{[Item="Sheet1",Kind="Sheet"]}[Data], [PromoteAllScalars=true]),
フィルター実行 = Table.SelectRows(ソース, each List.Contains(
Table.SelectRows(LOOKUPテーブル, each [天気予報]="雨")[都道府県名], //キーのリスト
[出身地]))[[氏名],[出身地]]
in
フィルター実行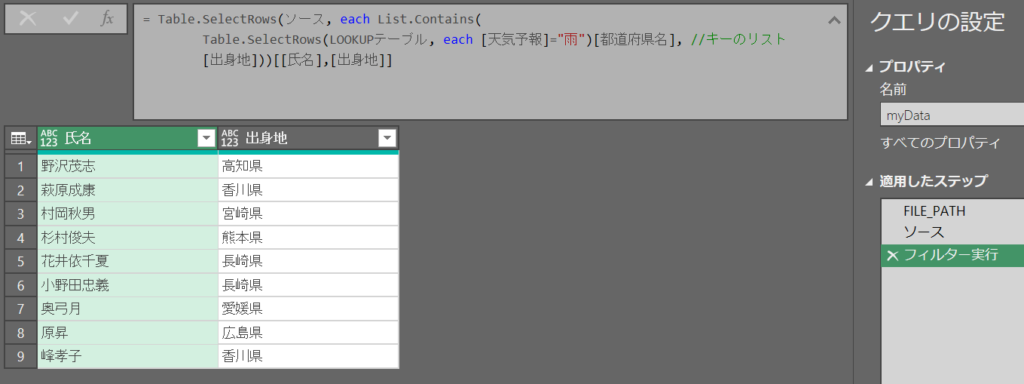
グループ化

実行例
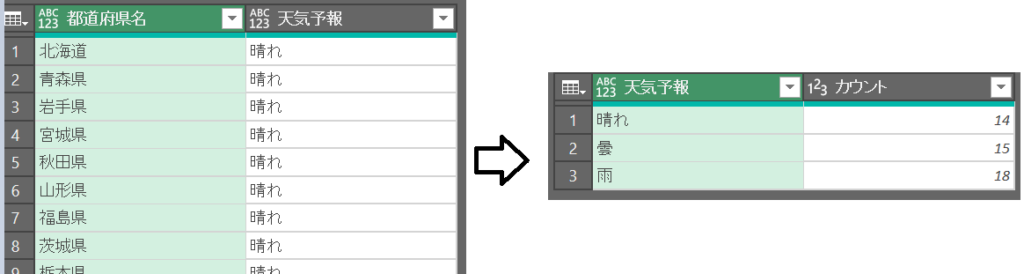
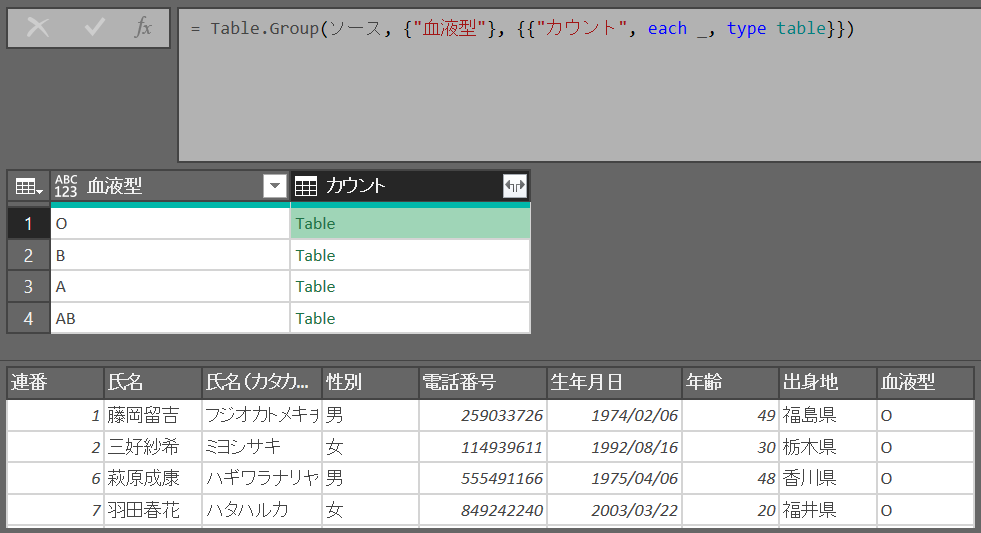
= Table.Group(ソース, {"天気予報"}, {{"カウント", each Table.RowCount(_), Int64.Type}})・第2引数:キー列の名前
・第3引数:集計列のリスト(1列ごとに{新しい列の名前、集計関数、データ型}というリストを格納する)
集計関数の種類
「each」の後に書く部分
合計:List.Sum([列名]), type number
平均:List.Average([列名]), type number
中央:List.Median([列名]), type number
最小:List.Min([列名]), type number
最大:List.Max([列名]), type number
行数のカウント:Table.RowCount(_), Int64.Type
個別の行数のカウント:Table.RowCount(Table.Distinct(_)), Int64.Type
※Distinctなので多分「重複を除く」という意味かな?まだ使ったことない
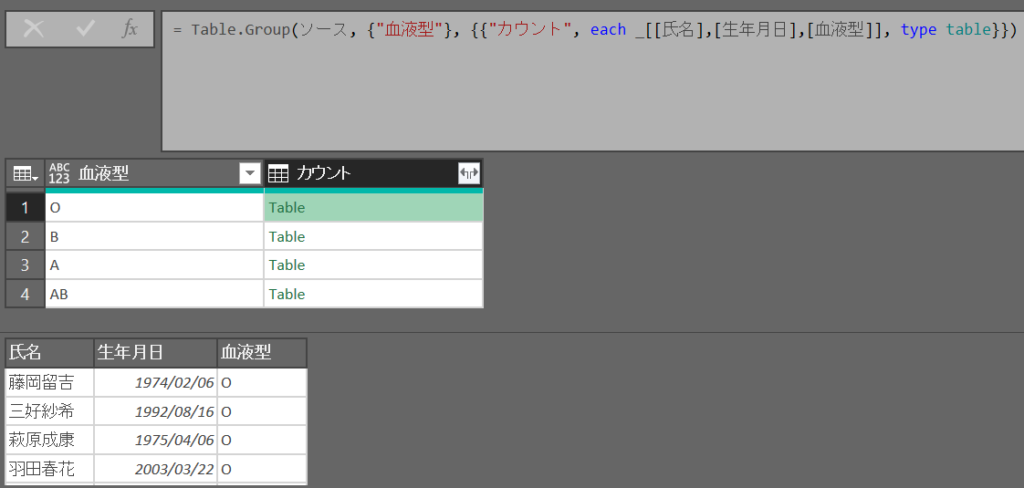
すべての行:_, type table
※キーでフィルターされたテーブルが付与され、展開できる状態となる
これを使えば、オリジナルの集計関数を自作して適用したりできそう
(ただし1行ごとに「展開」して処理するのでかなり重いと思われる)
列の抽出は可能と確認
テーブルの結合
マージ:Table.NestedJoin

第1、第2引数:メインテーブル、メインテーブルのキー列の名前
第2、第3引数:JOINするテーブル、JOINテーブルのキー列の名前
第4引数:新しい列の名前
第5引数:JOINの種類(省略可能。デフォルトは左外部)
マージ展開:Table.ExpandTableColumn

引数:テーブル名、展開対象の列名、展開する項目リスト、展開後の新しい列名リスト
行の追加:Table.Combine
