M言語基本
※使用データは「疑似個人情報生成」様で生成したダミーです
データの種類
テーブル
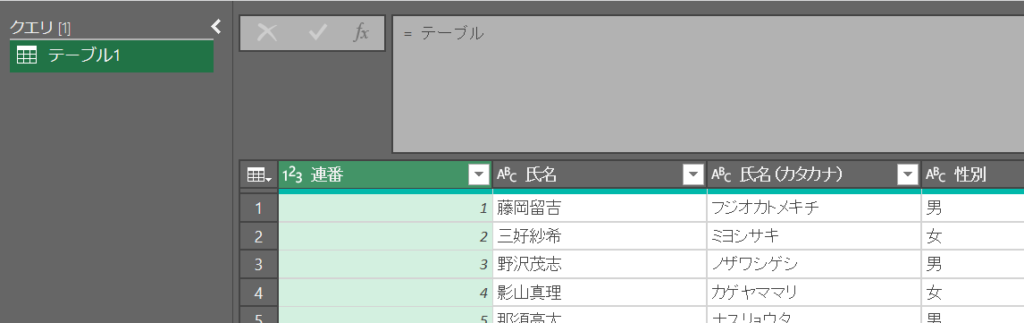
レコード
テーブルから1行だけ抽出すると「レコード」になる
「キー:値」という辞書型のような形
指定方法:テーブル名{数字}
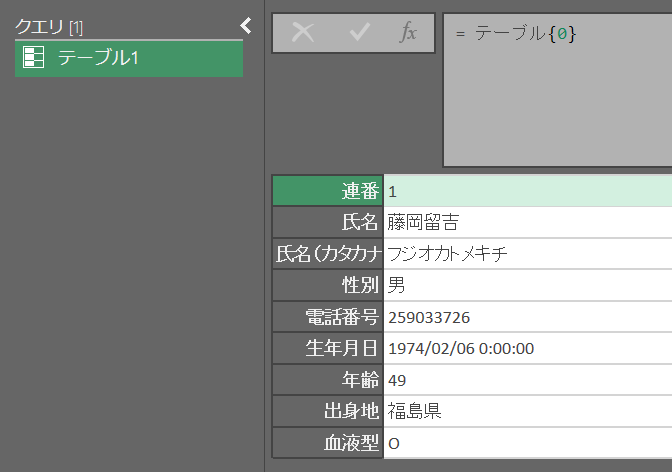
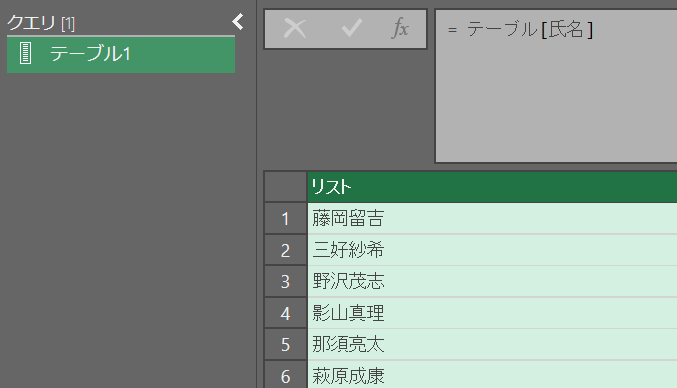
リスト
テーブルから1列だけ抽出すると「リスト」になる
番号順にデータを格納した一次元配列のような形
指定方法:テーブル名[列名]
値だけ取得(ドリルダウン)
レコードからドリルダウンするときは [] を使い、キーで指定
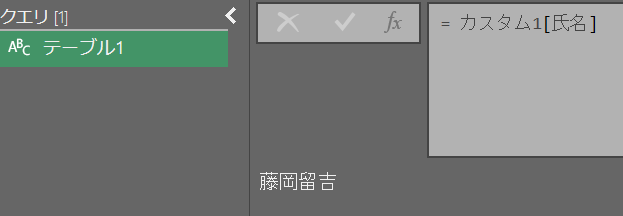
リストからドリルダウンする時は {} を使い、番号で指定
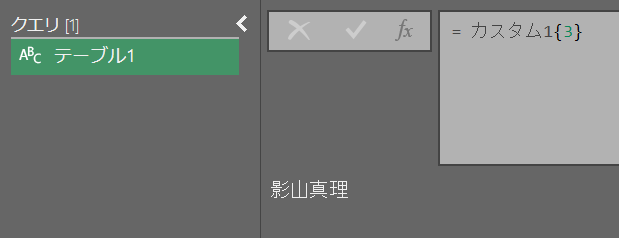
テーブルからドリルダウンする時は両方を組み合わせ

スペースなどがある場合:#" " で囲む
データの取得
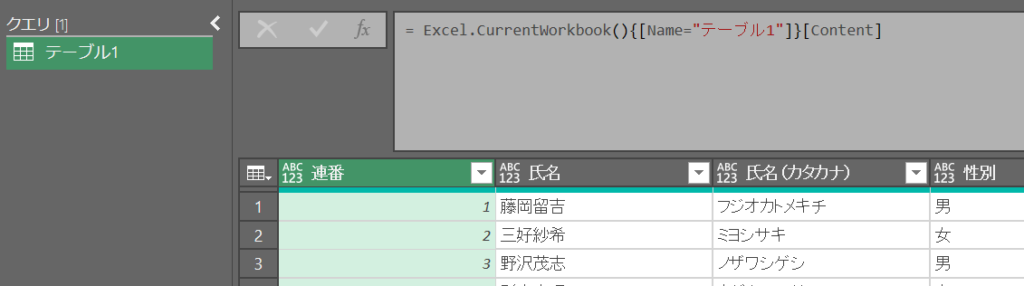
テーブルまたは範囲から
読み込んだ直後
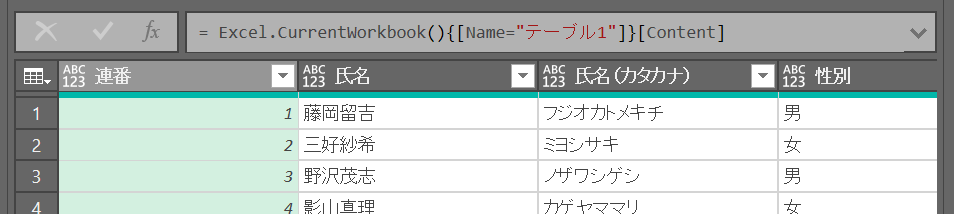
「= Excel.CurrentWorkbook()」はオブジェクトとオブジェクト名のテーブルを取得する模様
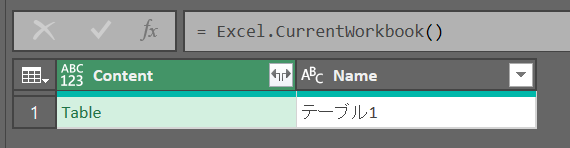
{}は行の指定
数字を入れると行番号で指定できる
行を文字列で指定したい場合は [列名=""] と書く
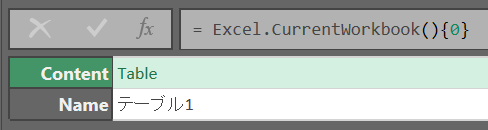
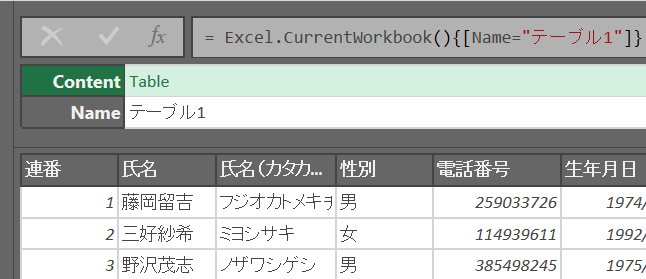
行をクリックすると下に中身のプレビューが表示される
レコードから [] でキーを選択すると中身が展開される
Excelブックから
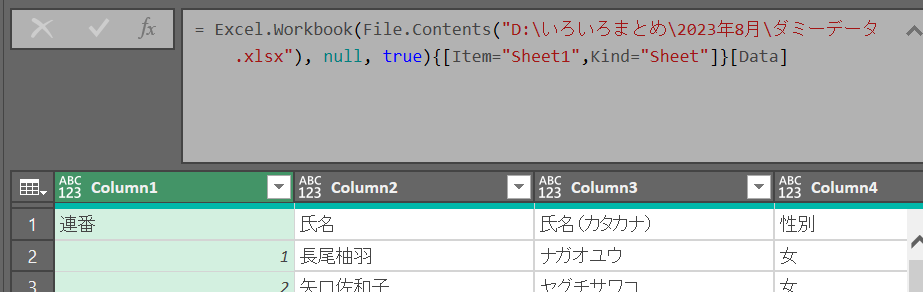
ファイルパスの指定
ソース = Excel.Workbook(File.Contents("ファイルパス"), null, true)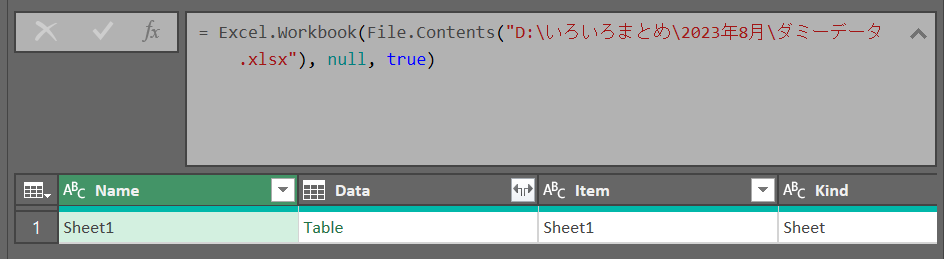
行を選択:{[Item="Sheet1″,Kind="Sheet"]}
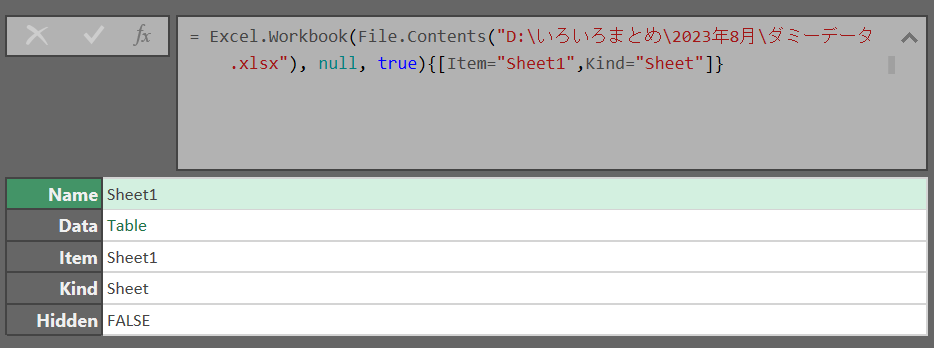
キーを選択:[Data]
1行目をヘッダーに昇格
ヘッダー昇格 = Table.PromoteHeaders(ソース, [PromoteAllScalars=true])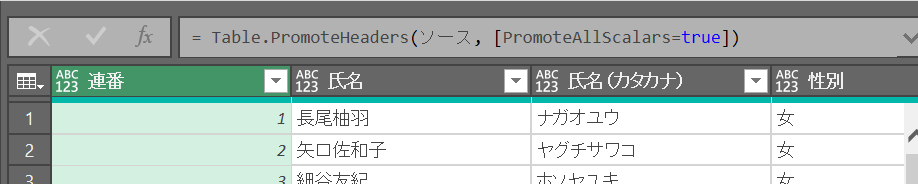
空のクエリ
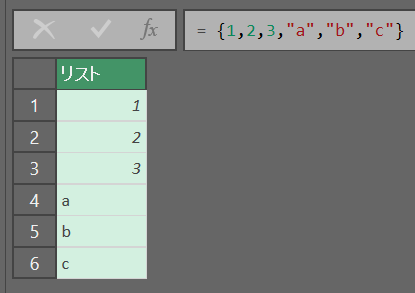
リストの作成
値を{}で囲むだけ
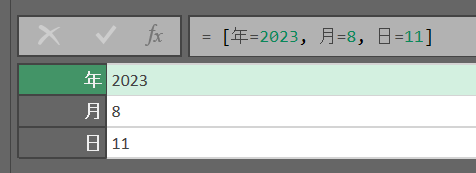
レコードの作成
キーと値のセットを [] で囲む
テーブルの作成
ハッシュタグ関数?と呼んでいいかわからないがこれが使える
(普通の関数と違って小文字である点に注意)
・第1引数:列名のリスト
・第2引数:行データのリスト(1行1リストずつ格納)
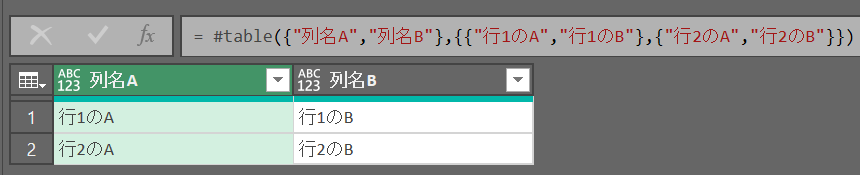
別のテーブルを参照
テーブル名を入れるだけ
別テーブルの1列をユニークリストにする
ソース = List.Distinct(テーブル1[血液型])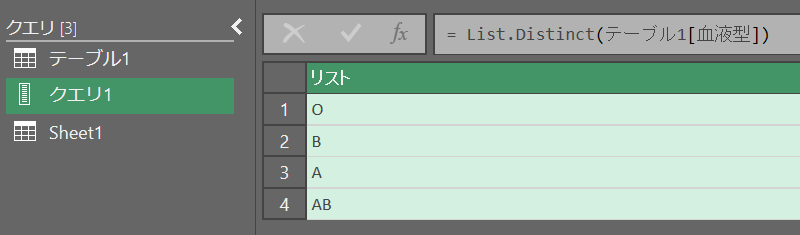
別テーブルから複数列を取得する
ソース = Table.SelectColumns(テーブル1, {"性別","血液型"})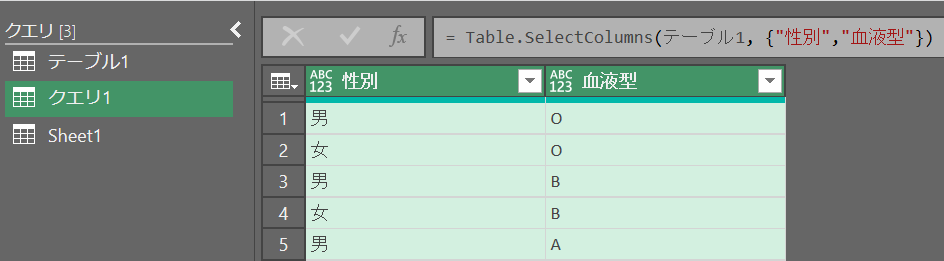
[] を入れ子にすると同じことができる
= テーブル名[[列名A],[列名B]]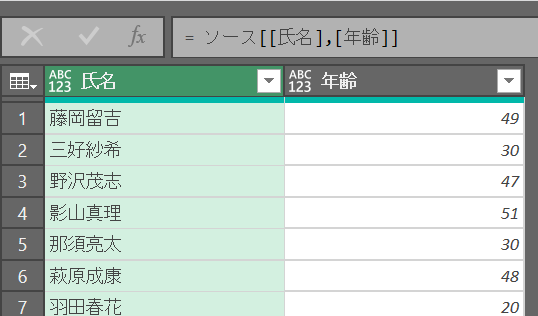
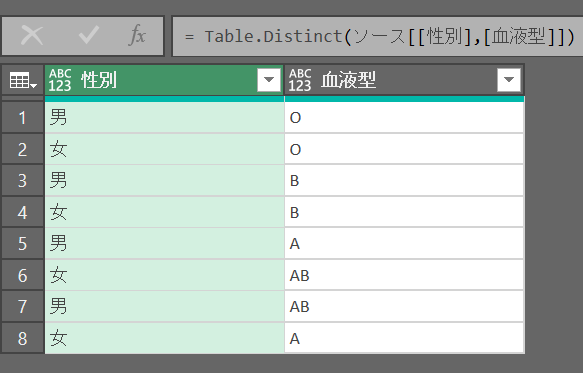
別テーブルから複数列を取得して重複を削除する
ソース = Table.Distinct(Table.SelectColumns(テーブル1, {"性別","血液型"}))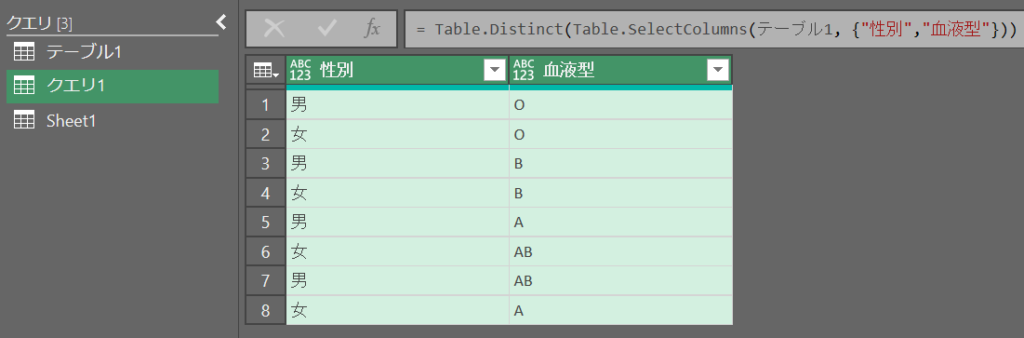
関数使わない版 こちらの方が書きやすい
クエリの追加(行方向の結合)
2つのテーブルで列の名前が一致してないときれいに結合されない
(列名が一致しない場合、その列が増えて全部nullになる)
ソース = Table.Combine({テーブルA, テーブルB})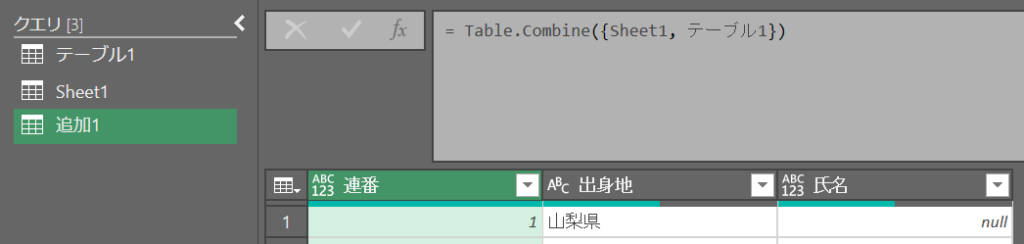
列と行の操作
列の選択と削除
選択した列だけ残し、他の列を削除する
列選択 = Table.SelectColumns(ソース,{"氏名(カタカナ)", "性別"})選択した列を削除する
列削除 = Table.RemoveColumns(ソース,{"氏名(カタカナ)", "性別"})行の保持
上位の行を保持
行の保持 = Table.FirstN(ソース,3)下位の行を保持
行の保持 = Table.LastN(ソース,3)行の範囲を保持
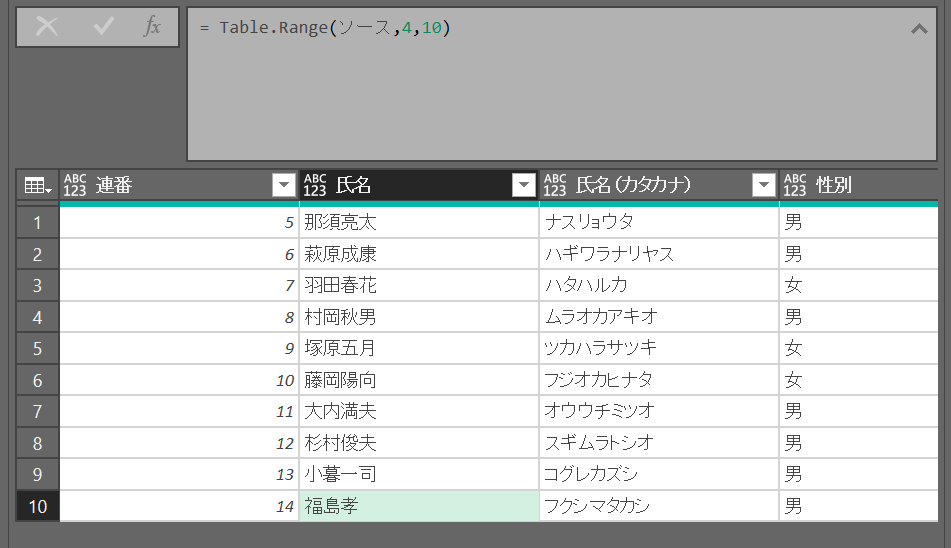
行の保持 = Table.Range(ソース,4,10)・第2引数の開始位置はゼロベースで指定(=1件目の開始位置は0)
・第3引数は終了位置ではなく「開始位置からx件分を保持」という意味
行の削除
上位の行を削除
行の削除 = Table.Skip(ソース,3)下位の行を削除
行の削除 = Table.RemoveLastN(ソース,3)代替行を削除
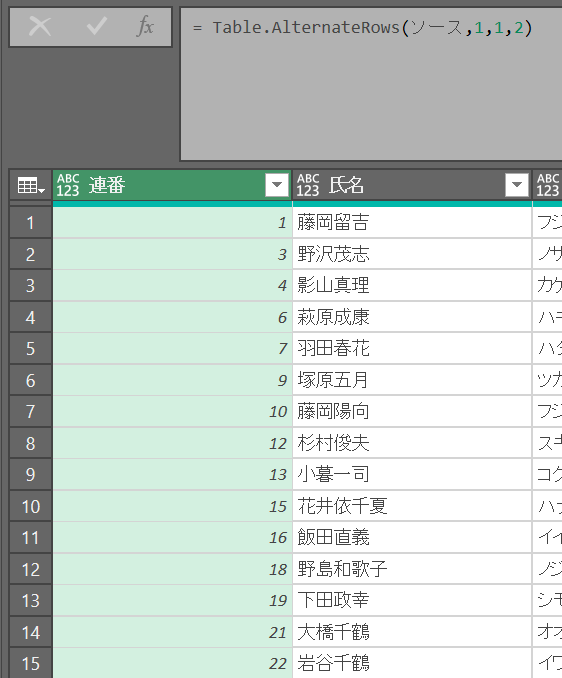
行の削除 = Table.AlternateRows(ソース,1,1,2)「代替」の意味が謎だが、実態は「削除する行のパターン」を指定できる
・第2引数:開始位置(ゼロベース)
・第3引数:削除する件数
・第4引数:残す件数
この例では1件消して2件残す、1件消して2件残す、…という繰り返しになっている
重複を削除
重複の削除 = Table.Distinct(ソース, {"出身地", "血液型"})空白行を削除
※テーブルにあるすべての列が対象になる様子
空白の削除 = Table.SelectRows(ソース, each
not List.IsEmpty(List.RemoveMatchingItems(Record.FieldValues(_), {"", null})))エラーを削除
エラー行の削除 = Table.RemoveRowsWithErrors(ソース, {"出身地", "血液型"})並び替え
昇順は「Order.Ascending」、降順は「Order.Descending」
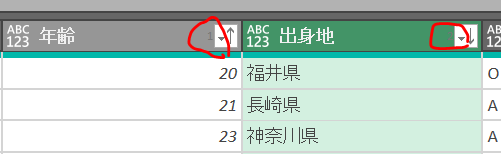
ソート優先順に数字がつくが、濃い灰色モードではほぼ見えない
単体の列でソートする
第2引数が二重リスト?になってる点が独特
並び替え = Table.Sort(ソース,{{"年齢", Order.Ascending}})複数列でソートする
第2引数のリスト内で、さらにリストをカンマ区切りする
並び替え = Table.Sort(ソース,{{"年齢", Order.Ascending}, {"出身地", Order.Descending}})変換
行数のカウント
行数 = Table.RowCount(ソース)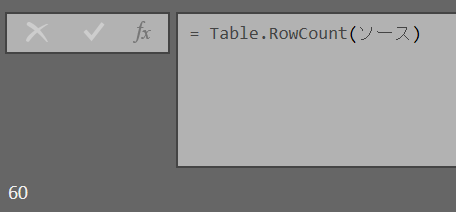
列の追加
Index列の追加
#"列追加:Index" = Table.AddIndexColumn(ソース, "インデックス", 0, 1, Int64.Type)・第3引数を1にすれば1からのIndexになる
カスタム列の追加
each の後が数式を書く場所
列追加 = Table.AddColumn(ソース, "カスタム", each [年齢]*2)条件列の追加
each の後にif文を書くだけ
条件列 = Table.AddColumn(ソース, "カスタム", each if [年齢] >= 18 then "成人" else null)フィルター
基本的なフィルター
単体の値でフィルター
each のあとに条件を()で囲む
フィルター = Table.SelectRows(ソース, each ([血液型] = "A"))複数の値でフィルター
()の中で or や and を使って条件を繋げる
フィルター = Table.SelectRows(ソース, each ([血液型] = "A" or [血液型] = "B"))部分一致でフィルター
よくある「*」などのワイルドカードは使えない
フィルター = Table.SelectRows(ソース, each Text.Contains([出身地], "京"))